Anonymisation d’une base de données Liferay

Anonymisation d’une base de données Liferay
Les réglementations et la confidentialité des données d’un utilisateur font partie prenante du métier de développeur et sont un aspect très souvent négligé. C’est pourquoi je vais vous présenter dans cet article différentes méthodes et aspects de l’anonymisation de données et notamment ce qui peut être intéressant à explorer si l’on souhaite anonymiser une base de données Liferay.
Chez Beorn, nos clients possèdent des données à caractères sensibles. C’est pourquoi il est important de les mettre en confiance sur ce point mais également de sécuriser nos développeurs sur les différents projets en proposant une copie d’une base de données avec des données factices.
Je m'appuierai ici sur le cas d'une base de données pour un portail Liferay 7.4, et pour lequel nous souhaitons anonymiser et garder une cohérence des données dans différents contextes Liferay.
Présentation générale du concept d’anonymisation
L'anonymisation de données est l'une des techniques qui peuvent être utilisées pour se conformer aux réglementations strictes en matière de confidentialité des données. Ces réglementations exigent désormais d'assurer la sécurité des informations personnelles identifiables, telles que les rapports de santé, les coordonnées d’utilisateurs, leur localisation ou les informations bancaires, parmi tant d'autres.
Différentes techniques d’anonymisation
Nous pouvons recenser de nombreuses techniques d’anonymisation telles que :
Suppression
Généralisation
Character Masking
Swapping
Synthetic Data
Micro-agrégation
Top Coding et Bottom Coding
Je ne peux que vous conseiller la lecture de cette thèse très intéressante portant sur le sujet des méthodes et outils d’anonymisation :
https://tel.archives-ouvertes.fr/tel-01783967/document
Dans notre cas, nous recherchons des méthodes pouvant être mises en place le plus simplement possible dans un gros volume de données, et pouvant être appliquées dans le contexte d’une base de données Liferay.
Ici je vais maintenant détailler les seules méthodes que je trouve personnellement les plus pertinentes à mettre en place dans le cas où l’on souhaiterait garder un maximum de cohérence du corpus de données.
Suppression
Dans la méthode de suppression, nous pouvons distinguer 2 cas différents :
La suppression globale : suppression de toutes les données d’un ensemble
La suppression locale : suppression partielle des données d’un ensemble en les remplaçant par une valeur NULLE ou une valeur mentionnant son retrait.
Exemple de suppression locale :

Character masking
Cette technique consiste à masquer complètement les données d’une table à risque sans permettre une quelconque identification. Ce masquage est généralement effectué avec un caractère * ou x.
A noter, que cela empêche la compréhension des données. Pour y remédier, il est possible d’utiliser le “character masking” de façon partielle, comme ci-dessous.
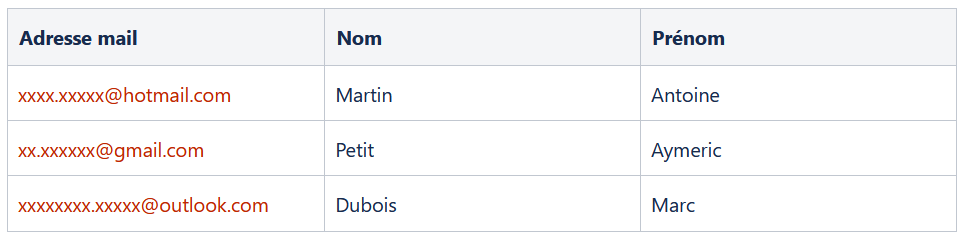
Synthetic data
La méthode “synthetic data” permet de remplacer les données d’une table à risque par des données artificielles. Elle permet également de préserver les informations, les modèles et les corrélations des données sources.
Les données synthétiques utilisées sont des informations générées par un algorithme sans rapport avec un cas réel. Les données sont utilisées pour construire des ensembles de données artificielles au lieu de modifier ou d'utiliser l'ensemble de données d'origine et de compromettre la confidentialité et la protection.
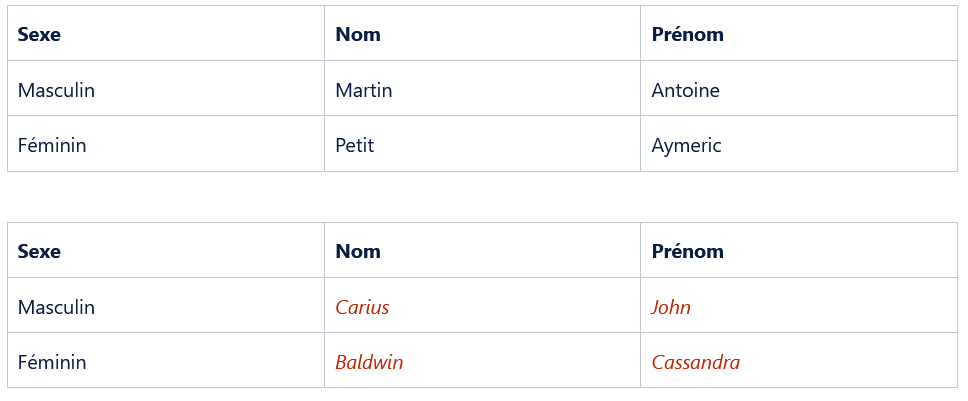
Les champs sensibles d’une base de données Liferay
Les tables comportant des données sensibles
Voici une liste non exhaustive des différentes tables de la base de données qu’il est important de connaître lorsque l’on souhaite anonymiser les données liées à un utilisateur.
Table user_
La table user_ est la principale table à anonymiser. En effet, c’est ici que l’on va retrouver de nombreuses informations sensibles :

/!\ Attention à l'utilisateur par défaut et à l’utilisateur Anonymous Anonymous qui ne doivent pas être modifiés.
A noter que par la même occasion, pour garder une cohérence dans la base de données, il est important de mettre à jour tous les champs userName et statusByUserName de toutes les tables de la base de données Liferay, respectivement associés à un utilisateur.
Le champ statusByUserName implique 43 tables de la base de données. Le champ userName en implique 253.
Table address
La table address contient toutes les adresses qui ont pu être ajoutées par un utilisateur dans l’édition de son profil : il est également important d’effectuer un traitement d’anonymisation dessus.

Table contact_
La table contact_ contient tous les contacts d’un utilisateur. Ne pas oublier les champs pouvant contenir les identifiants facebook, skype, etc.

Table emailAddress
Cette table contient les différentes adresses mails d’un utilisateur.
Table phone
Cette table contient les différents numéros de téléphone d’un utilisateur.
Table group_
Étant donné que les utilisateurs ont vu leur screenName modifié, il est important de modifier le champ friendlyUrl correspondant au groupe de l’utilisateur (qui permet de gérer ses pages personnelles et sa fiche publique) dans la table group_ en fonction du nouveau screenName.
Les tables pouvant contenir des données sensibles
Nous pouvons également noter que tous les champs textuels de la base de données peuvent potentiellement contenir des données sensibles, telles que les champs content, description, comments, et bien d’autres.
Par exemple, dans un commentaire ou un contenu d’article, un utilisateur peut avoir signé le message avec son nom et son prénom.
Plusieurs problématiques peuvent être alors relevées :
Récupérer ces champs sensibles;
Détecter si une valeur est sensible dans chacun de ces champs;
Isoler cette valeur et effectuer l’une des méthodes d'anonymisation possibles en évitant de modifier la structure des données qui peuvent contenir des balises XML, HTML, du JSON, etc.
Les solutions à envisager
Les solutions à adopter diffèrent en fonction du besoin et de ce que l’on souhaite obtenir comme résultat.
L’outil proposé par Liferay : Anonymous User
Liferay propose un outil permettant de supprimer les données d’un utilisateur. Pour cela, il se base sur un nouvel utilisateur, Anonymous Anonymous, qui fonctionne comme un échangeur d’identité. Lors de la suppression d’un utilisateur, Liferay nous propose soit de supprimer toutes les données associées soit de les anonymiser. Lors du choix de l'anonymisation, il remplace l’utilisateur de chaque donnée par l’utilisateur Anonymous.
Cet échange d'identité est une étape importante dans le processus d'anonymisation, mais une intervention manuelle supplémentaire peut être nécessaire pour parvenir à une véritable anonymisation. Par exemple, le contenu d’un article ne sera pas anonymisé car l’outil de Liferay ne détecte pas si des données pouvant identifier une personne sont présentes dans le contenu d’un article. Pour y remédier, il proposera la suppression totale des articles d’un utilisateur. Et nous perdrons alors un grand nombre de données lors de l’anonymisation.
De plus, si cet outil est utilisé pour plusieurs utilisateurs, toutes les données seront associées au nouvel utilisateur Anonymous. Cela peut ne plus rendre les données cohérentes entre elles.
Par exemple, en imaginant que deux utilisateurs ont échangé par messages, ce sera maintenant la même et unique personne, Anonymous Anonymous, qui sera l’expéditeur et le destinataire des messages.
Cependant, il est important de relever que dans le cadre de la création d’une entité personnalisée via le Service Builder, Liferay offre la possibilité de mettre en place la fonctionnalité d’anonymisation.
Je ne peux que vous renvoyer vers l’article de Ibai Ruiz pour plus de détails sur cette approche :
https://liferay.dev/blogs/-/blogs/anonymize-your-custom-entities-and-comply-with-gdpr-the-easy-way-
Outils de type ETL
Des outils spécialisés dans l’intégration de données, tels que Talend ou Pentaho, sont capables de fournir un service d’anonymisation grâce à l’exécution d’un traitement d’anonymisation dans un flux de données.
Après récupération des données depuis des sources d’entrée non anonymisées (base de données, fichiers, etc.), nous pouvons effectuer notre traitement d’anonymisation sur les données sensibles et recréer une nouvelle source anonymisée.
Un outil tel que Talend propose un composant d’anonymisation si l’on souscrit à une offre Big Data. Cependant il est toujours possible d’effectuer nos propres opérations et traitements sur le flux de données afin d’anonymiser celles-ci, en passant par la création d'algorithmes et de tests en Java.
Usage de scripts
En dernier choix, nous pourrions opter pour une méthode personnalisée qui associerait les 3 types de méthodes d’anonymisation présentées. Cela permettra également d’avoir la main-mise sur toutes les données et tous les champs de la base de données.
Pour le cas des données sensibles “cachées” pouvant être contenues dans des champs textuels tels que la description d'un article de blog, nous pourrions proposer une détection de données sensibles (pouvant être associées à une personne) avec un script et la proposition à un administrateur d’anonymiser ou non ces données avec les différentes méthodes.
Cela offre également une certaine liberté dans le choix de la génération de valeurs factices.
En quelques mots
Chez Beorn, nous avons opté pour la solution de script. J’ai pour cela développé un outil en Python permettant d’anonymiser les données d’une base de données Liferay en utilisant différentes méthodes d’anonymisation, tout en gardant une cohérence dans les données. Le point le plus délicat est certainement la détection de données sensibles dans tous les champs d’une base de données, mais à l’heure actuelle, il existe des outils capables de faire du NER (Named-Entity-Recognition) et ainsi de pallier cette problématique.
À l'heure actuelle, l’outil développé supporte une base de données MySQL Liferay et est en mesure d’anonymiser toutes les tables contenant des données sensibles, en conservant un contexte entre les utilisateurs et en conservant une cohérence dans les données. Contactez-nous pour en savoir plus sur notre outil.
Il est également capable de détecter, en partie, si tous les champs textuels de la base de données contiennent des données sensibles (relatives à une personne, une localisation). Suite à cela, l’administrateur de l’outil est informé des données détectées et peut également décider de les anonymiser avec une méthode de Character Masking.
La fiabilité de l’outil est une métrique à prendre en compte. Bien évidemment, comme tout outil basé sur l’intelligence artificielle, quelques exceptions peuvent passer au travers.
Dans un futur proche, l’objectif sera de prendre en charge d’autres SGBD tel que PostgreSQL. Mais aussi d’ajuster l’aspect NER et proposer différentes techniques d’anonymisation pour répondre à de nombreux besoins.
J'espère pouvoir vous partager prochainement cette solution d’anonymisation !
Merci de m’avoir lu et à bientôt!